
One
of my more popular recent posts was one entitled A Table Listing
50 Things Science Cannot Explain. I discussed fifty puzzling
mysteries modern science has not been able to solve. But my table
failed to mention one of the biggest unsolved mysteries in science:
the mystery of protein folding.
Basic
molecular building blocks of the body, proteins are specified in DNA
by a one-dimensional series of nucleotide base pairs that represent a
series of amino acids. A particular protein may be specified in DNA
by a gene that is a simple series of nucleotide base pairs that stand
for a series of amino acids (the building blocks of proteins). In
the visual below, we see a simple gene that specifies the contents of
the protein, and (in colors of orange, blue, yellow, and green) some of the nucleotide base pairs that make up the
gene. The chromosomes are found in every cell.

Certain
combinations of these nucleotide base pairs (guanine, cytosine,
adenine, and thymine) represent particular amino acids (because the
cells use the genetic code). A protein is composed of these amino acids. Below
is a schematic diagram of a small hypothetical protein. Other
proteins might consist of not just 13 amino acids, but hundreds of
them.
Protein
343
|
Lysine
|
Valine
|
Glycine
|
Leucine
|
Threonine
|
Leucine
|
Tyrosine
|
Serine
|
Valine
|
Leucine
|
Lysine
|
Serine
|
Threonine
|
Now,
based on what you have just been told, you might think that proteins
are long string-like molecules like the long string-like molecule
that is the DNA molecule. In other words, you might think that a
protein looks like the chain we see in the visual below. A series of
amino acids such as this, existing merely as a wire-like length, is
sometimes called a polypeptide chain.

But
protein molecules instead typically have intricate three-dimensional
shapes. So a protein molecule isn't shaped like a simple length of
copper wire – it looks more like some intricate copper wire
sculpture that some artisan might make.
Below are two examples of the 3D shapes that protein molecules can take.
There are countless different variations.
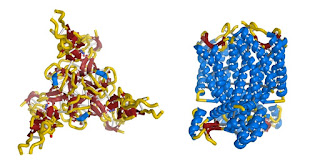

The
phenomenon of a protein molecule forming into a 3D shape is called
protein folding. How would you make an intricate 3D sculpture from a
long length of copper wire? You would do a lot of folding and bending
of the wire. Something similar seems to go on with protein folding,
causing the one-dimensional series of amino acids in a protein to end
up as a complex three-dimensional shape.
The
question is: how does this happen? This is the protein folding
problem. Biochemists have been knocking their heads on this problem
for 50 years, and have made very little progress in solving it.
An
idea considered very early in the investigation of the protein
folding problem is that after a protein is created, it reaches a
particular shape through a kind of trial and error chemical “search.”
It was thought that maybe newly created protein molecules kind of
cycle through different structural arrangements until one stable
arrangement was found; and that the protein shapes we observe are
just the results of such a search.
But this idea was ruled out pretty quickly. In 1969 scientist Cyrus Levinthal calculated that a protein with about 100 amino acids could be folded into about 3 to the 198th power shapes. Trying so many possibilities would take very many years – eons actually. But instead a particular protein will very rapidly form into a characteristic three-dimensional shape, in a very short time – seconds for small proteins, and minutes for large proteins. This discrepancy between the calculated time protein folding should take and the actual time it does take is known as Levinthal's paradox.
But this idea was ruled out pretty quickly. In 1969 scientist Cyrus Levinthal calculated that a protein with about 100 amino acids could be folded into about 3 to the 198th power shapes. Trying so many possibilities would take very many years – eons actually. But instead a particular protein will very rapidly form into a characteristic three-dimensional shape, in a very short time – seconds for small proteins, and minutes for large proteins. This discrepancy between the calculated time protein folding should take and the actual time it does take is known as Levinthal's paradox.
Levinthal's
paradox bothered those working on the problem of protein folding, and
they developed an idea to soothe their pain in this regard. The idea
was called Anfinsen's dogma. The idea behind Anfinsen's dogma is that
the three-dimensional shape of a protein is determined solely by the
sequence of amino acids in it.
We
can represent the Anfinsen's dogma with the visual below. The idea is
that given some particular chain of amino acids (also called a
polypeptide chain), and given the laws of chemistry, you will
automatically get some particular complicated 3D shape like the shape
below.

Anfinsen's Dogma
Scientists
have had more than 40 years to prove Anfinsen's dogma. But they still
haven't proven it. We still have essentially no understanding of how
laws of chemistry could make it so that some particular chain of
amino acids would have to take the complicated 3D shapes we see in
proteins.
It
seems likely that if Anfinsen's dogma were true,
scientists would have proven it by now, and would have solved the
protein folding problem. For long ago scientists were able to come
up with two sets of data: the three dimensional shapes of many
proteins, and the corresponding chain of amino acids that correspond
to such a shape. Now given these two sets of data, it would not take
very long to unravel some set of chemical rules forcing the chain of
amino acids to have that particular shape, if such rules existed.
If
it were true that 3D protein shapes are determined solely by a string
of amino acids and a set of chemical laws, this would be something
resembling encoding. One of the principles of cryptography is that if
you have a large number of samples showing information before it was
encoded, and the corresponding information after it is encoded, then
it is usually fairly easy to figure out what rules are being used for the
encoding.
Here
is an example. Imagine we have a table with many cases like those
below. Given such data, it is quite easy to figure out what the
unstated rules are that are causing these transformations. In this
case the rules are (1) shift each letter by one position in the
alphabet; (2) then reverse the input.
| Before Rules Are Applied | After Rules Are Applied |
| cat | ubd |
| frog | hpsg |
| desk | ltfe |
Now,
in the case of protein folding, we have something similar to the
table below. For quite a few years we have known the following things
about many proteins: (1) the one-dimensional sequence of amino acids
that make up the protein (the polypeptide chain); (2) the
three-dimensional shape that the protein takes. Given such data, and
given modern computerized technology, it should be fairly easy to
figure out what rules of chemistry might cause a sequence of amino
acids to become a particular three-dimensional shape – if indeed
the three-dimensional shape is actually determined merely by a
combination of that sequence of amino acids and some rules of
chemistry.
For
decades many scientists have been trying to solve this problem, and
they have even used super-fast supercomputers to try to solve it. But
they still have not come up with the answer. They still have not come
up with the answer to the protein folding problem. We know exactly
what the benchmark for success would be: if you had the problem
solved, then given a sequence of amino acids that make up a protein,
you would be able to correctly predict the three-dimensional shape of
the protein (without having seen it). No scientist has done anything
close to achieving such a benchmark.
But
given the amount of effort that has been applied to the protein
folding problem, it seems that a solution to the problem should have
been discovered if Anfinsen's dogma is correct.
As
one scientist states:
Then there is the existence of what are called metamorphic proteins. These are cases in which a protein can have different three-dimensional shapes or folds, despite there being a single underlying sequence of amino acids. This paper estimates that as many 4% of proteins are metamorphic or "fold-switching" proteins.
Therefore,
it is likely that Anfinsen's dogma is not correct. The structure of a
three-dimensional protein is probably not determined merely by the
combination of the sequence of amino acids in it and some laws of
chemistry.
What
is astonishing is that both in the case of protein folding and in the
case of morphogenesis (the progression from a fertilized egg to a
human baby), we seem to have a crucially important structural
progression that is almost completely unexplained by modern science.
Morphogenesis cannot occur merely by reading instructions from DNA,
because contrary to popular misconceptions, DNA cannot store any
blueprint or sequential list of assembly instructions for making
complex organs. DNA is basically just a long sequential list of amino acids,
and there seems to be no way of stating in DNA any such thing as a 3D
blueprint. See here for several reasons why the whole idea of a body
plan stored in DNA is erroneous. DNA is like a big stack of cards in
which each card simply has printed on it the name of an amino acid.
You can't express body plans or 3D blueprints with such a thing.
Expressing a body plan would require some language vastly more
expressive than the “bare bones,” minimalist, “amino acid”
language in which DNA is written.
What
goes on in morphogenesis (the progression from a fertilized egg to a
baby) is something currently inexplicable and profoundly
mysterious. Somehow a barely visible speck (a fertilized egg)
progresses to become a full baby, but we don't even know from where
it gets the body plan for a human being, which does not seem to be
stored in DNA (something that seems to be mainly an ingredient list,
not a structural blueprint).
It
is only reasonable to wonder whether such structural progressions
occur from some vitally important component of nature that is
completely unknown to us. The attempts of scientists to try to
explain these mysterious progressions in terms of what is known
(rather than admitting that there must be some great fundamental
unknown) are clumsy and unconvincing. When they find that what we
know is insufficient to explain what we observe, our physicists and
cosmologists seem to have no problem introducing hypothetical ideas
such as dark matter and dark energy, in an effort to fill the gap.
But our biologists seem to be lacking in theoretical imagination, and
seem to follow the rule: always try to explain observed biological
effects by using only what has been discovered already, no matter how
far-fetched such explanations may be.
Imagine
you are an astronaut who travels to some strange planet revolving
around another star. You notice an astonishing thing. Whenever it
snows heavily on this planet, the snow forms into snowmen. So when
it snows heavily, a large field might fill up with 10 snow men, even
though no visible person is building such snow men. Faced with such
a reality, you could mess around with bizarre theories trying to
explain such an outcome naturally (such as far-fetched “special
wind pattern” type of nonsense). Or you could be candid and admit
the strange reality: that there is some mysterious force on the alien
planet that likes to build snow men out of snow. Similarly, given
our inability to explain protein folding and morphogenesis, we might
be wise to admit that there is some mysterious life force on our
planet that wants to turn polypeptide chains into the 3D protein
molecules needed for life, and that wants to turn a newly fertilized
egg into a baby.
Below
is a relevant quotation from a medical doctor (the late Ian
Stevenson, MD):
The
statement was made in 1997, but is just as applicable today. And
since the decoding of the human genome was completed in 2003, it is
hard to believe claims that the answers to such questions will be
found in DNA. We've already analyzed human DNA and its gene
information completely, and the answers to the riddles of human
structure and 3D protein structure aren't there.
Here
is an interesting analogy. Let us imagine some person who has come to
America from some primitive land. The person lives next to a car
factory, and he is curious about how cars are made, something he
knows nothing about. But he is too embarrassed to reveal his
ignorance by asking. So he decides to break into the car factory in
the middle of the night, on several different nights. One night he
sees a bunch of parts lying around on the factory floor. The next
night he sees a partially assembled chassis on the assembly line. The
next night he sees a half-assembled car on the assembly line. The
last night he sees a nearly completed car.
If
this person had no knowledge of how factories worked, and was lacking
in imagination, he might hazard a guess that would be very wrong. He
might think somehow the parts knew how to assemble themselves into
the car. Our
scientists may be making a very similar mistake. The structural
progression known as protein folding may occur only because some
mysterious agency or some mysterious force acts to form polypeptide
chains into complicated 3D shapes. The structural progression known
as morphogenesis may occur only because some mysterious agency or
some mysterious force acts to gradually change a newly fertilized egg
into a full-size human baby over the course of nine months. But
knowing nothing about such an agency or force, our scientists try fruitlessly to
explain these structural progressions based on only what they do
know.
Almost as inexplicable is the progression from the densely packed and disorganized “quark soup” of the Big Bang to the universe we see today filled with beautiful orderly spiral galaxies. The diagram below compares these three structural progressions, and asks whether all three of them involve some mysterious structural forces completely beyond our current understanding.
Almost as inexplicable is the progression from the densely packed and disorganized “quark soup” of the Big Bang to the universe we see today filled with beautiful orderly spiral galaxies. The diagram below compares these three structural progressions, and asks whether all three of them involve some mysterious structural forces completely beyond our current understanding.

A new scientific study tells us that protein folding is "surprisingly more complex than previously known." We are told, "The JILA team identified 14 intermediate states—seven times as many as previously observed—in just one part of bacteriorhodopsin, a protein in microbes that converts light to chemical energy and is widely studied in research." It's as if some invisible factory worker (highly trained and very knowledgeable) was running through some very complex series of assembly instructions (not stored in DNA) to make the 3D shape of a protein out of the linear sequence of amino acids listed in DNA. We find again and again that our existence or our health depends on the final output being just right. How improbable is it that blind chemistry is all that is involved here?
Postscript: In yet another case of the premature triumphalism so common in science journalism, the New York Times gives us this wildly inaccurate claim:
They've been stumped by one great mystery: how the building blocks in proteins take their final shape. David Baker...has been investigating that enigma for a quarter of a century. Now, it looks as if he and his colleagues have cracked it.
No, not at all, for two reasons:
(1) The article later tells us that the reported success is only for "short-chained proteins." The median length of a protein in the human body is 431 amino acids. The heart of the problem is how proteins with hundreds of amino acids are able to form their 3D shapes. A solution working only for short-chained proteins isn't any real solution of the problem.
(2) The reported technique uses database techniques in which statistical data on a vast number of proteins is collected and used to predict a 3D shape. But from the standpoint of answering how nature could do protein folding, such a technique is kind of cheating. A polypeptide sequence has no database of thousands of protein shapes it can use when a 3D protein shape appears from a linear polypeptide chain of amino acids. The protein folding problem has always been: how could a complex shape appear from only the data in a linear polypeptide chain of amino acids?
Postscript: A year 2026 paper makes it clear that contrary to boasts in the press, the AlphaFold2 software does not actually solve the protein folding problem, the problem of how protein molecules almost instantly acquire very complicated 3D shapes needed for their function. The year 2026 paper states, "The explanatory scientific understanding of the protein folding problem is thus
not directly advanced by AF2 [AlphaFold2]." Later the same paper says, "The protein folding problem remains unsolved." Instead, the AlphaFold2 software makes progress on a different problem, properly described as the protein structure prediction problem, which is the problem of predicting the 3D shape of a protein molecule from its amino acid sequence. Whenever one of the more complex types of protein molecules almost instantly takes the very complex 3D shape needed for its function, it is a miracle of warp-speed purposeful assembly.
No comments:
Post a Comment